
What Makes a Good Movie?
Objective: To collect movie data including ratings, visualize the movie attributes against the ratings to determine any correlations, and build a tree based model to predict movie ratings.
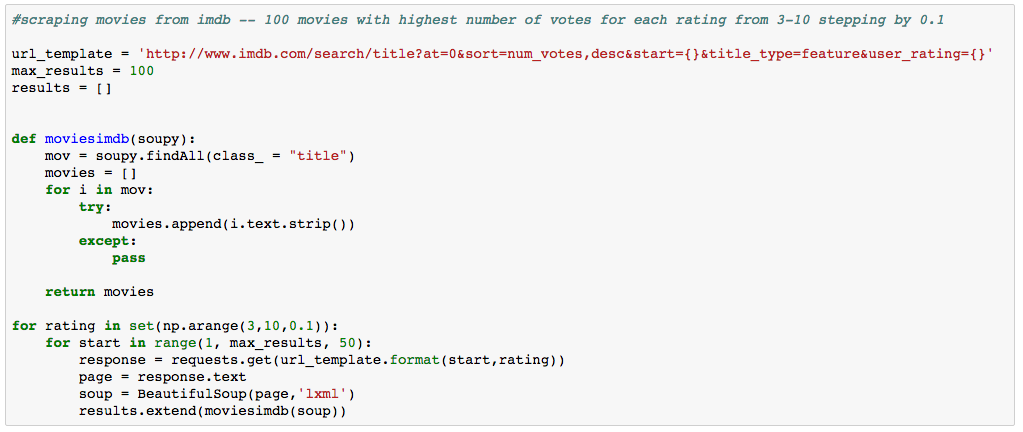
The first step is to find a reliable dataset from which we can build a strong model. I started by using the 1000 best movies of all times according to the New York Times, but I decided that a model to predict rating should also include bad movies as well. From IMDb.com, I scraped 100 movies with the highest number of votes from each rating between 3 and 10 stepping by 0.1. Code below:
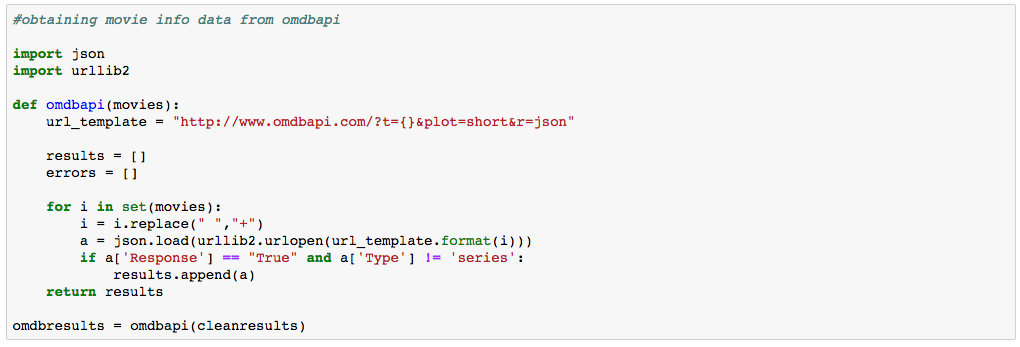
The next step is to download as much information about each movie as possible. For this, I used OMDb API and loaded the data to a dataframe. Code below:
Before any analysis, the data required of a lot of prepping:
- Deleting columns not needed for the model such as Actors, Plot, Title, etc.
- Dropping any movie with missing data (excluding Awards or MPAA rating).
- Converting runtime, number of votes, and year to integers and IMDB rating to a float.
- Dropping any movie with less than 500 votes.
For simplicity, I binarized Awards and Language. If the word ‘Oscar’ was mentioned either by nomination or win, the value was set to 1, otherwise 0. And the language was broken down to either being released in English or not. For country, I set the country to the first listed (if there were multiple) and included any country with at least 25 movies. The rest were set to other. Dummy variables were then created for country, MPAA rating, and genre.
The Data
Now that we’ve finished cleaning, we can now take a closer look at the data.
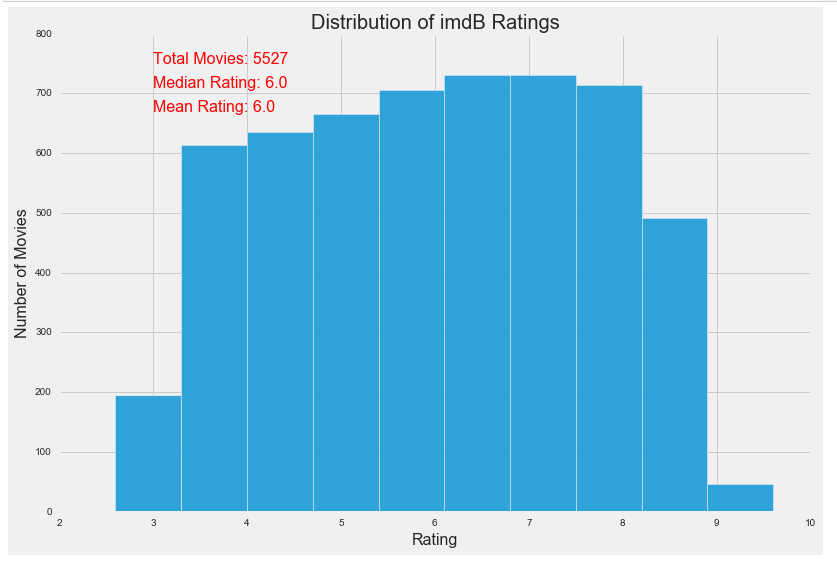
The dataset includes 5,527 movies with a relatively balanced distribution of IMDb ratings. There is a deficiency of movies rated above 9 simply because there aren’t many movies with such a high rating and more than 500 votes.
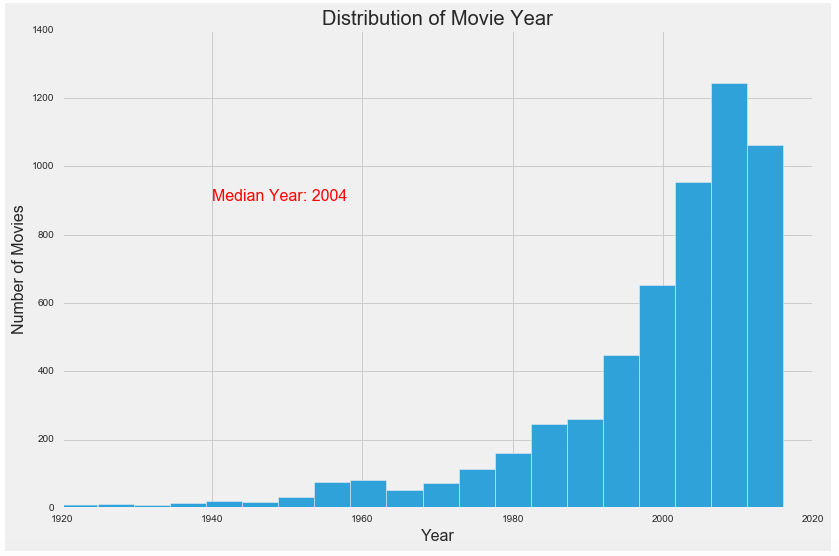
We should also note that the data clearly skews to movies released more recently with a median release year of 2004.
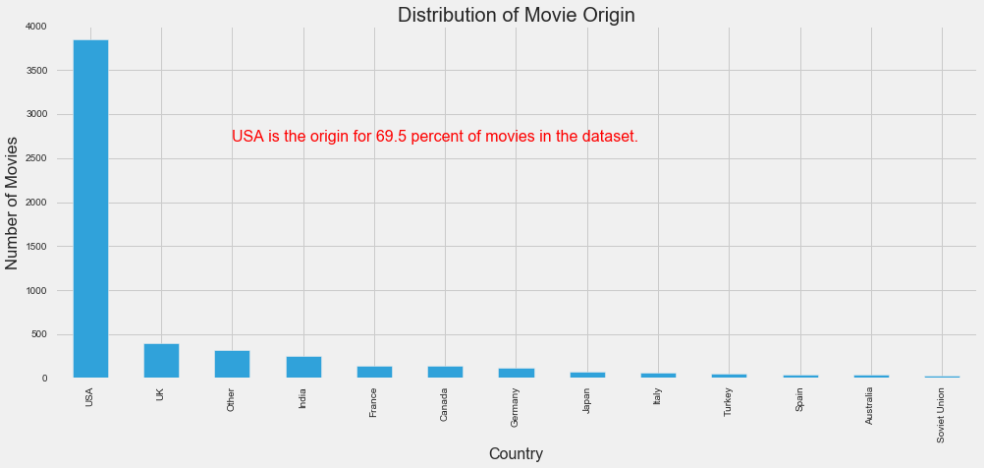
Also, a majority of movies in the dataset were released in the United States as can be seen below.
Enough about distribution, let’s see what actually impacts IMDb rating. Below are three graphs showing rating plotted against number of votes, movie runtime, and release year, respectively.
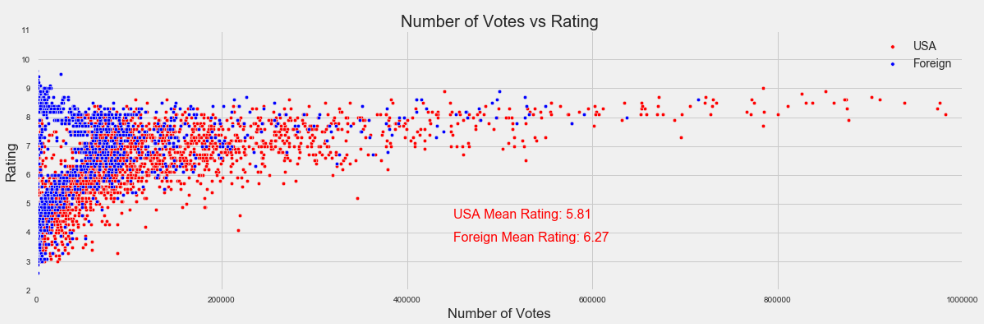
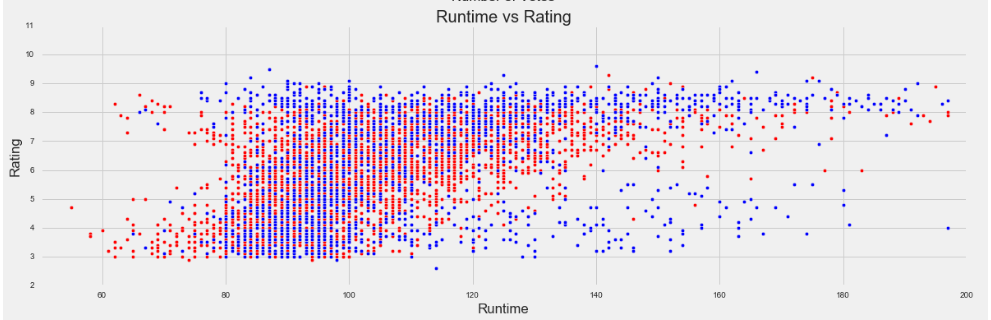
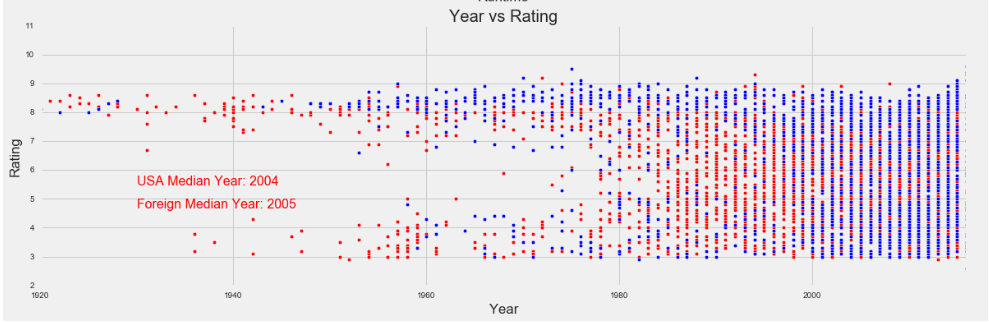
The interesting takeaways from each are:
Number of votes
- There is a clear positive relationship between number of votes and rating. Almost every movie with more than 200k votes has an above average rating.
- Foreign movies are more likely to have a higher rating across the board. The mean rating for American movies is 5.81 while the mean for foreign films is 6.27.
- A movie receiving more than 200k votes is far more likely to be American. More than 84% of movies with 200k votes were from the USA.
- There is a high concentration of foreign movies with a very high rating and few votes. In fact, less than 13% of movies with a better 7.0 rating and less than 36k votes were from the USA.
Runtime
- There is a positive relationship between the length of the movie and its rating. For movies with runtimes less than and greater than 120 minutes, the mean rating is 5.6 and 7.2 respectively. For movies longer than 180 minutes, the mean rating is a shocking 8.1!
- Movies longer than 2.5 hours (150 minutes) are likely to be foreign by almost 2:1.
- If a long movie (runtime greater than 120 minutes) has a low rating (less than 5), it is overwhelmingly likely to be a foreign film. More than 86% of movies with these qualifications are not American.
Release Year
- Only 5.5% of movies before 1980 have an “average” rating (with average being between 5 and 7) – meaning as people rate older movies, their impressions are almost binary, and these movies have either very high or very low ratings as a result. Also, movies from this time period that are average don’t stand out and are less likely to be receive votes in the first place. An older movie that’s either great or awful is more likely to receive the attention and also the votes.
Model Building
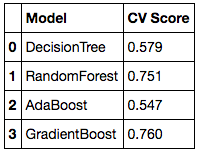
We can now run our models. I chose to fit four regression models (Decision Tree, Random Forest, AdaBoost, and Gradient Boosting) and compare to see which performs best. After splitting the data into training and testing data, fitting the models, running the predictions, the CrossVal scores can be calculated. We can also see which features are most important in predicting the IMDb rating. Below are CrossVal scores for each model. We can see the GradientBoosting model performed best with a CV score of 0.76.
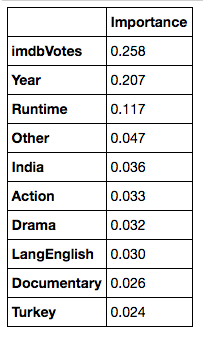
The three most important features are, not surprisingly, number of votes, movie runtime, and year released for reasons laid out above.
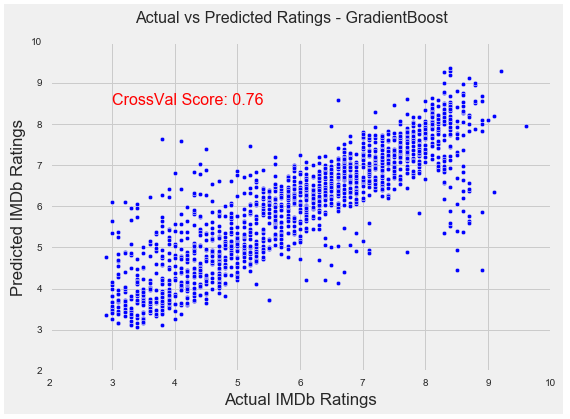
Finally, we can graph the predicted ratings from the GB model against the actual ratings from the test set to visualize model performance. We can see the model predicts rather well but with more errors at the high and low end of the dataset with respect to rating. This is most likely due to less data available in these ranges.
Next Steps:
While this model is a great start in predicting ratings, there are a few areas for improvement that should be explored.
- Additional data should be obtained with ratings at the extremes, especially higher rated movies.
- This model does not take into account actors, writers, or directors. These can absolutely influence a movie’s rating.
- Pulling data from additional ratings websites should be considered. While IMDb may be the most popular, it certainly isn’t the only one.